Esse é mais um dos artigos que apresentam uma visão peculiar do Go frente às demais linguagens. Quando falamos sobre performance em programação, geralmente associamos o tema à complexidade algorítmica, uso de paralelismo ou pool de conexões. Mas quando tratamos de Go, por ser uma linguagem mais "pé no chão" (menos camadas de abstração), temos mais controle sobre certos detalhes que, em outras linguagens, mal percebemos. A forma como criamos structs é um desses detalhes.
 Esse meme pode ser um exagero? Talvez não.
Esse meme pode ser um exagero? Talvez não.
E se eu te disser que a ordem dos campos de uma struct pode impactar diretamente a performance em Go? Claro, não é nem de longe a única coisa que vai tornar um software mais eficiente. Performance é um conjunto de fatores. Mas esse aqui é daqueles ajustes finos que podem fazer diferença, principalmente quando estamos lidando com sistemas de larga escala.
Como assim, ordem dos campos em struct?
Vamos aprofundar a problemática usando um exemplo.
Exemplo 1 - Struct original
package main
import (
"fmt"
"unsafe"
)
type Consumer struct {
ID int8 // 1 byte
Active bool // 1 byte
Score float64 // 8 bytes
Name string // 16 bytes
Balance float32 // 4 bytes
Age int16 // 2 bytes
}
No código acima, usamos unsafe.Sizeof para imprimir o tamanho total, em bytes, da struct Consumer.
fmt.Printf("Size of Consumer: %d bytes\n", unsafe.Sizeof(c))
// Saída: Size of Consumer: 40 bytes
Exemplo 2 - Campos reorganizados
Agora, vamos fazer uma leve modificação. Iremos reordenar os campos da struct Consumer pelo tamanho, do maior para o menor:
type Consumer struct {
Score float64 // 8 bytes
Name string // 16 bytes
Balance float32 // 4 bytes
Age int16 // 2 bytes
ID int8 // 1 byte
Active bool // 1 byte
}
Executando novamente o código:
fmt.Printf("Size of Consumer: %d bytes\n", unsafe.Sizeof(c))
// Saída: Size of Consumer: 32 bytes
Conseguimos uma economia de 8 bytes só com essa reorganização. Isso mostra como uma mudança aparentemente inocente pode fazer diferença.
Organização, padding e word size
Mas por que isso acontece? Por que a ordem dos campos muda o tamanho da struct? A explicação está em como a memória é organizada e como a CPU trabalha com alinhamentos. Fazendo um raio-x dos campos da struct, a soma total resulta em 32 bytes:
| Campo | Tipo | Tamanho |
|---|---|---|
| ID | int8 |
1 byte |
| Active | bool |
1 byte |
| Score | float64 |
8 bytes |
| Name | string |
16 bytes |
| Balance | float32 |
4 bytes |
| Age | int16 |
2 bytes |
Soma: 1 + 1 + 8 + 16 + 4 + 2 = 32 bytes
Para saber o motivo da primeira versão ter reservado 40 bytes, precisamos entender os conceitos de word size e padding.
word size
Imagine que toda vez que a CPU busca algo na memória, ela acessa "palavras" inteiras por ciclo de clock. Essa palavra tem tamanho fixo. É o que chamamos de word size. Em sistemas de 64 bits, uma word equivale a 8 bytes. Já em sistemas de 32 bits, são 4 bytes. Neste exemplo, vamos considerar um sistema de 64 bits.
padding
Os dados da struct precisam ser alinhados em posições de memória que sejam múltiplos de seu próprio tamanho. Isso facilita o trabalho da CPU, que consegue acessar os dados mais rápido. Se por um lado, aumentamos a eficiência ao acessar a memória, por outro, isso pode gerar espaços "vazios" entre os campos, chamados de padding.
Visualizando o clock
Vamos imaginar cada bloco de 8 bytes como um "ciclo de clock", começando pela struct desorganizada:
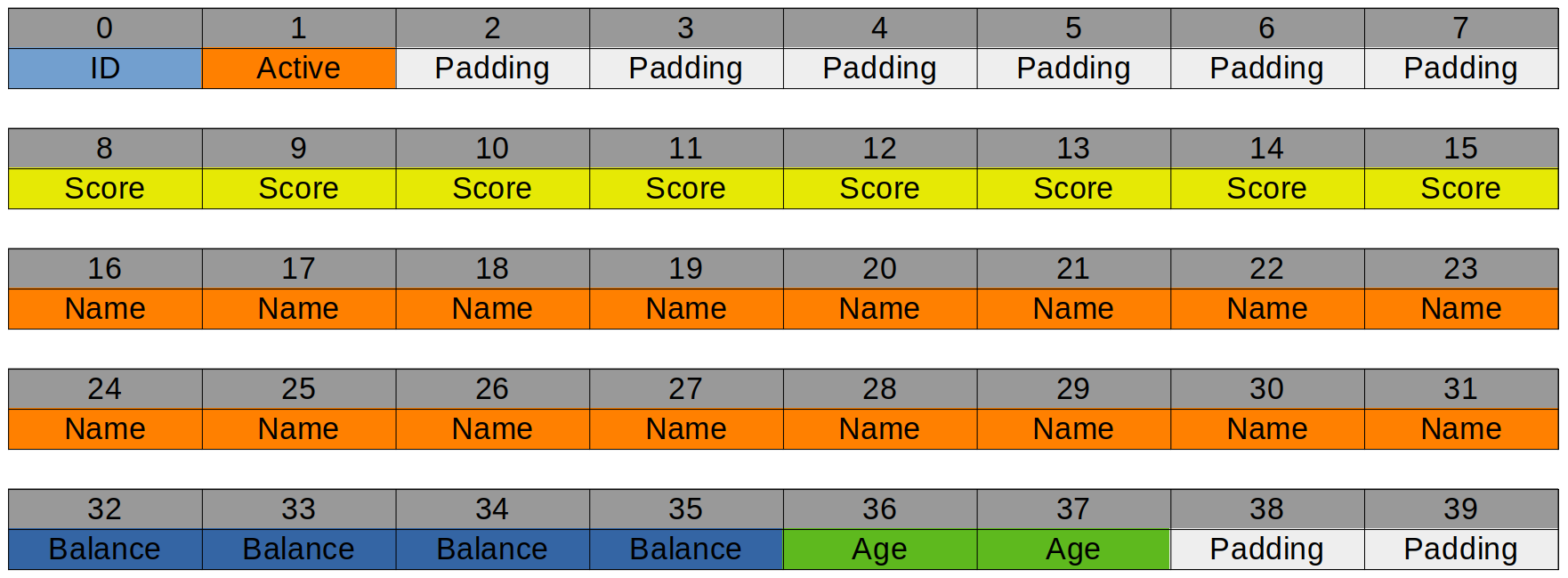 Struct desorganizada.
Struct desorganizada.
Veja que ID e Active, por estarem no início, ocupam as duas primeiras posições de memória. No entanto, a variável Score não pode começar logo em seguida. Ela precisa aguardar até o próximo bloco de 8 bytes, já que, por ter exatamente esse tamanho, só pode ser alocada em um endereço múltiplo de 8. Já os campos Name, Balance e Age conseguem se encaixar sem maiores problemas após isso. As posições de memória que ficam vazias nesse processo são chamadas de padding.
Podemos dizer, então, que tivemos um desperdício de 8 bytes (devemos contar sempre os paddings para medir).
Agora vamos vizualizar a organização com a mudança na ordem de definição de campos da struct:
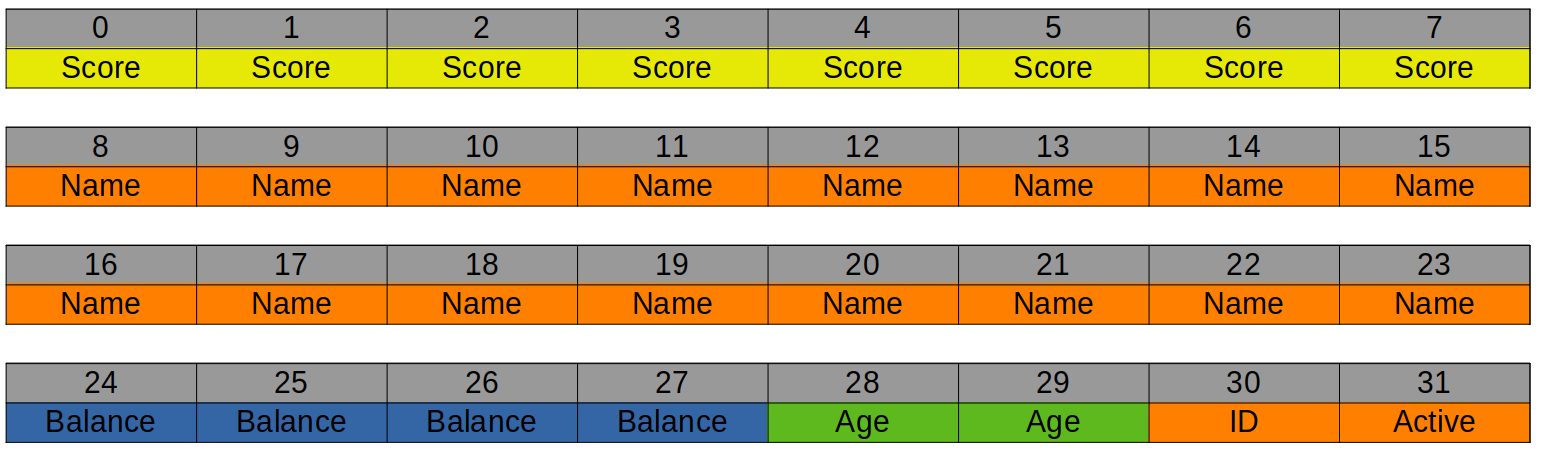 Struct organizada.
Struct organizada.
Agora, com a nova ordem dos campos, o Score ocupa perfeitamente o primeiro bloco de 8 bytes. Em seguida, o Name, que tem 16 bytes, preenche os dois blocos seguintes sem desperdício. No quarto bloco, temos o Balance (4 bytes) seguido por Age (2 bytes), ID (1 byte) e Active (1 byte), encaixando exatamente os 8 bytes disponíveis. Com isso, eliminamos os espaços vazios da versão anterior e conseguimos economizar 8 bytes de memória de forma simples e eficiente 🚀.
Ferramenta de análise fieldalignment
Em Go existem ferramentas que analisam automaticamente a struct e faz as correções necessárias visando a otimização. Uma dessas ferramentas é o fieldalignment. Para fazer a sua instalação execute o comando abaixo:
go install golang.org/x/tools/go/analysis/passes/fieldalignment/cmd/fieldalignment@latest
Para usar, é bastante simples! Basta rodar o comando fieldalignment ./.... Você verá algo como:
diego@diego-workstation:~$ fieldalignment ./...
main.go:8:15: struct of size 40 could be 32
Após isso, para efetuar as alterações, basta passar o argumento -fix neste comando:
fieldalignment -fix ./...
Considerações finais
Neste post, vimos que até mesmo pequenas mudanças (que às vezes passam despercebidas) podem impactar bastante o ciclo de vida de um software. Quando falamos de Go, então, isso fica ainda mais evidente. Me conta nos comentários quais outros cenários em Go são sensíveis e podem ser verdadeiros game changers quando o assunto é performance? 😊
Até a próxima :)